Aruspix has been developed with early typographic music prints in mind, meaning mainly those scores printed during the 16th and 17th centuries with movable typefaces. Such scores are often difficult to examine with existing superimposition and optical recognition software, as they present a number of specific layout and format problems and are quite often in a deteriorated state because of their age.
The printing techniques of that time mean that differences can exist between copies produced in the same print run, and comparison of these copies by superimposition can enable more accurate critical editions to be prepared. Digitalising the scores through optical recognition can enable us to collate different editions regardless of layout, and will also be useful in the preparation of digital music libraries, for example.
In the course of a thorough examination of various 16th and 17th century editions of musical partitions, it turned out that copies of the same edition can contain differences, in the form of either handwritten annotations or scratched corrections carried out directly on the form. The presence of such differences between copies is not systematic and it is not possible to determine that one copy is of better quality than another.
The automatic superimposition process that is part of Aruspix means being able to pick out differences between two copies of a score emanating from a single print run, without the need for laborious hand-and-eye comparison, and with colours to distinguish the features of each copy.
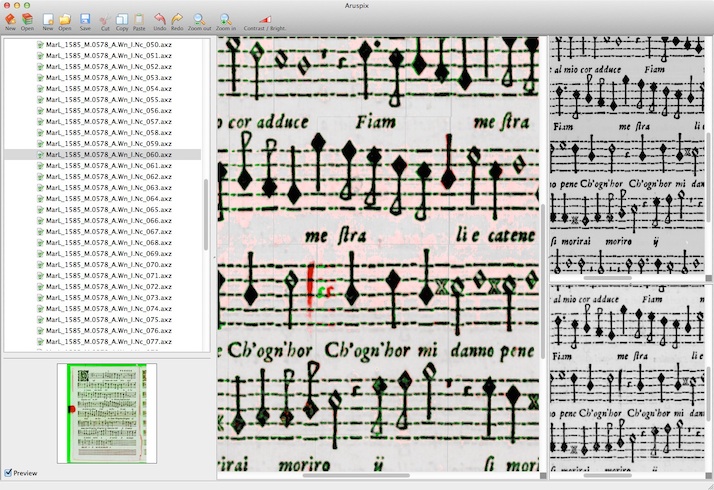
The optical recognition part of Aruspix uses an innovative technique in OMR based on Hidden Markov Models to identify and classify the particular musical characters found in early music prints, after an initial pre-treatment phase performed on scanned images of microfilm and facsimiles. The integrated music editor allows corrections of any recognition errors.
One major originality of Aruspix is that it learns and optimizes itself dynamically as soon as a page is processed and corrected by the user.
The collation process enables different editions and re-editions of a book to be collated automatically. It is based on the digital representation of the content of the books generated by the optical recognition process, which enables the books to be collated even when the layout is not the same. In the user interface, the differences are highlighted in color, and clicking on them automatically locates and highlights the original image.
The project is funded or plays a significant role in the following grants:
Laurent Pugin (lead developer)
Etienne Darbellay
Ichiro Fujinaga
Andrew Hankinson
Rodolfo Zitellini
John Ashley Burgoyne
Greg Eustace
Tristan Himmelman
Tristan Matthews
Christopher Niven
Alastair Porter
Marnie Reckenberg
Gabriel Vigliensoni
